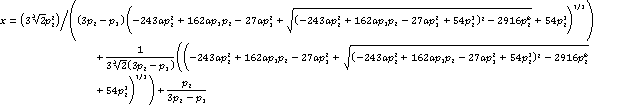|
Democracy in Peer Reviewing On how to avoid dictator PC chairs and other adventures. The computer science academic world is witnessing an almost exponential increase in reported research results. To handle this deluge, young conferences and workshops appear, and established conferences find themselves having to significantly reduce acceptance rates, often to almost statistically irrelevant rates of 10% and below. In this climate, program committee (PC) members and chairs of such selective conferences are faced with the job of choosing the best papers out of their individual reviewing pile and the conference as a whole. As a result, the individual reviewers process is constantly dominated by the more often than not rhetorical question is this paper is in the top 15% of my pile? And, as expected, the answer is mostly no. Yet, simple statistics show that this is the wrong question to ask, by a factor of up to 4! In fact, using this question as guidance only leads to a significant dilution of its askers impact in the resulting conference program and unnecessarily offloads much of the selection process onto the PC chair and the subset of vocal reviewers attending the PC meeting where final decisions are made. This in turn results in lack of transparency and (often justified and bitter) feelings of frustration on the side of the submitting authors, and overall questions about the fairness and democracy of the process. We discuss here how to restore democracy to the conference reviewing process and introduce the R3 reviewing rule to guide individual reviewers to maximize their impact in the conference program. 1. Overview Tens of thousands of papers (re)circulate yearly through the CS academic and research system with the ultimate goal of eventually finding a good home. Conferences. It is hardly news that advances in CS academic research are first and foremost reported in (annual) peer-reviewed conference proceedings (and less so in journals, for reasons mostly centered in the fast-paced nature of the field). As a result, conferences have become the venue of choice for most computer science academics, researchers, and tenure committees. By the Numbers. Computer Science features over 250 major peer-reviewed research conferences [1] and a total exceeding thousands, including affiliated workshops and smaller conferences (DBLP lists 3900 [2]). ACM alone organizes over 125 conference events with hundreds of associated workshops [3]. Most of these venues are more or less selective, with acceptance rates ranging from 9% all the way to 50% and above [4]. 2. Acceptance Rates and Paper Quality. Acceptance Rate Targets. Most conferences start by a priori targeting a number of available presentation slots and an approximate acceptance rate ballpark. Of course, this is not ideal, and a conference chair would rather not have to preset an acceptance rate target but instead accept all publication-worthy papers. In practice however, this is not tenable for obvious reasons. Conferences need to be able to plan for presentation rooms, hotel accommodations, meals etc. well in advance, often as early as 2+ years. Further, most conferences maintain a relatively fixed multi-day format which limits the number of viable presentation slots. In the case of NDSS (discussed below), instance-specific preparations start a full year in advance and hotel capacity is reserved at least 7-9 months in advance. Paper Quality. Common wisdom suggests that the more selective a conference, the higher the quality of its accepted papers. Unfortunately, this is also not as simple, and quite often reduced acceptance rates do not translate in better papers and vice-versa. To see why this is the case, consider the fact that there are two acceptance rate vantage points. One of them is the perspective of an individual paper P and defines the probability that the paper gets accepted into a conference C with acceptance rate A after a number of resubmission to other conferences. The second vantage point is defined by the acceptance rate A of a given conference C. Now consider the first, paper vantage point. The intuitive assumption that we start from is that papers have some quantifiable inherent absolute quality Q, e.g., ranging in (0,1). In that case, one would expect that Q and A are quite strongly inversely correlated. Unfortunately while this mostly holds for the extremes of the distribution of Q, what actually happens in reality is quite different for mediocre papers results that are neither stellar, nor completely trivial by definition the vast majority of published work. Consider an obviously stellar result with a high Q. In the absence of human inertia and conservatism, it is quite likely to get accepted within very few tries into a low acceptance rate conference, where conversely, a clearly straightforward result would have asymptotically zero chances. If we repeat the experiment across multiple resubmissions it is unlikely to significantly change the correlation effect on average. However, consider a mediocre paper, somewhat above the threshold of triviality. This residual amount of value may just be enough to ensure a non-zero probability of random acceptance in a selective venue with an acceptance rate much better than the paper's Q. If the paper authors flip their lucky coin a sufficient number of times, in a somewhat memory-less environment, by resubmitting their virtually identical paper after each rejection to different venues, its residual value and the associated non-zero probability of random acceptance may just be enough to get the paper accepted eventually. And unfortunately this is exactly what is happening in reality virtually identical papers get circulated again and again [5] until accepted. So far, in the past 10 years, my personal record is reviewing 3 separate papers 5+ times each in different venues (seeing the same un-modified paper submitted 2-3 times is routine and not even worth mentioning). Despite reviewer feedback, in 2 of these cases, the authors have not changed anything in any of their subsequent re-submissions. The 3rd paper underwent a few cosmetic changes each time. Subsequently I have seen two of these papers eventually published in top 3 venues. Kudos to the persistent authors! Thus, here is a strategy I would recommend to ambitious young assistant professors having to satisfy their unreasonable 5-10 paper/year tenure committee expectations: do not compromise; submit your minimal effort mediocre papers only to good conferences until they get in. This would have the added advantage of making you many good friends amongst the reviewers that will have to review your identical paper 3-4 times in a row and thus won't have to work too hard the 2nd, 3rd and 4th times. But then, since most mediocre yet persistent coins flip on the winning side eventually, we realize that the quality of a given paper should not be inferred solely from the selectivity of the conference it was published in. A more accurate evaluation of quality would start by endowing the system with memory somehow as has been proposed and tried repeatedly in the past in some communities. Alternately, at least aggregate of the set of all acceptance rates of conferences to which a paper has been submitted until its eventual acceptance. It would be interesting to quantify this further. The conference vantage point can be equally bleak. At an extreme, if all the submitted papers are in fact resubmissions, the accepted top 15% of the incoming pile may in fact only lie in the top 30-60% of all the areas papers created in that year (also a function of total number of other conference alternatives). This effect is compounded by geo and demographic effects that drive (solely) submission numbers up. For example it is well known that the recent trend of organizing English-speaking conferences in China yields significant submission rates and often very low acceptance rates. Thus, conference selectivity may not say much about the inherent quality of the program in relationship with other conferences. Recent results are more encouraging however. Chen and Konstan [8] have "found that papers in low-acceptance-rate conferences have higher impact than those in high-acceptance-rate conferences within ACM, where impact is measured by the number of citations received. [...] also [...] highly selective conferences [...] are cited at a rate comparable to or greater than ACM Transactions and journals. " This indeed confirms the leading role that conferences have in the CS field. What it does not do however is escape the inherent circularity of the argument: (a) most selective conferences receive a large number of submissions and can thus afford to be low-acceptance-rate (b) large numbers of submissions stem from the fact that large numbers of researchers know about the conferences (c) this in turn results in a proportionally larger number of citations on average Thus, it is not clear why this is not a simple self-fulfilling prophecy and what in fact the result shows regarding the relationship between acceptance rates and impact. 3. To Meet or Not To Meet Since we are in an optimistic streak we shall now get closer to our main topic: PC chair dictatorships. For this, we need to first discuss the PC meeting phenomenon. When selecting papers, once acceptance rates are set and the written review process has completed, program composition seems to be a matter of simply selecting the top 15% of the papers in order of their ranking. In practice things are not as simple and many if not most CS conferences traditionally augment an initial online discussion phase with a program committee (PC) meeting during which its members or at least the subset that actually come and participate, discuss in person the merits of individual papers or lack thereof. In general, while such meetings are wonderful opportunities to enjoy a spectacle of vocal democracy often dominated by a set of opinionated members of the committee, the PC meeting concept is fraught with three immediately evident problems. First, the process is skewed towards PC meeting participants' opinions. Nevertheless, individuals that cannot make it to the meetings cannot be blamed as much as was possible a decade ago -- with the mushrooming set of conferences today, experts are often asked to serve on 10-15 committees each year and may agree to do so for 5-6. Participating to 6 in-person PC meetings each year is stretching schedules extremely thin, especially for researchers with a busy research, publication and conference presentation schedule. The result is that often, while agreeing to be on a PC and also performing the intensive written reviewing process, visible researchers are unable to participate to more than 1-2 in-person PC meetings -- yet these are exactly the people that one may want to consult. Second, for each paper, out of the participants that actually make it, only 3-4 have actually read the paper and spent time thoroughly thinking about it. The rest of the PC members are very unlikely to be able to spend more than very few minutes cursory looking at the paper and uttering an opinion. In a meeting for conferences with 250+ submissions, this becomes a fuzzy, tiresome process with often little ultimate value and potential to alienate authors and taint the process perception of fairness. Finally, and most importantly, very often PC meetings are unfortunately dominated by vocal or well-debating members that effectively silence more quiet participants. It is no secret that we academics are an opinionated bunch and unfortunately this may be an instance where it does not help. Debating skills of a paper's reviewers are hardly good criteria for its scientific evaluation, at least if one buys the democratic version of the conference peer-review story. Why PC Meetings? All is not lost however. There seem to be three scenarios in which PC meetings bring value. One scenario is the case of an expert researcher participant that has not had a chance to read the paper so far, but who nonetheless would have decision-overturning value to add to the discourse. This actually happens less often than one would hope after all, the expert would have to contend with the currently assigned paper reviewers and their decision, while starting from the point of having to read the paper in the first place. The second scenario involves assigned reviewers' feeling of lack of expertise and request for additional opinions. In my experience, this happens more often than it should in PC meetings yet there is no reason why this situation cannot be handled by a diligent PC chair in the written reviews and online discussion phase by assigning additional expert reviewers, and not let escalate all the way to the PC meeting. The third and final scenario is the most obvious one. Despite numerous attempts, and significant efforts by the PC chair, reviewers have not reached a consensus in the written phase, and are hoping to do so face to face, possibly aided by the aid of visuals or rotten tomatoes. It is unclear what the intuition is that suggests 4 people that have not reached agreement in an often extensive online written discussion phase, will suddenly agree when face to face, other than skills that may not have anything to do with the inherent quality of the discussed paper. Decisions before PC meetings. Overall however, in my mind, the balance seems clearly tilted towards thorough written evaluations and discussions and away from verbal debating skills. Written evaluations are simply more tenable, easier to document, and ultimately debate. To ensure judicious use of time, PC meetings can and should only handle borderline cases for which consensus was not possible in the written phase despite best diligence. 4. Democracy The implicit assumption in modern CS conferences so far has been that the program is the result of the submitted paper qualities filtered through the expertise and beliefs of the PC members, ultimately a democratic expression of the PC and its composition. Job of PC chair. In a democracy, the PC chair should play little more than an impartial shepherd allowing the process to function properly and ensuring PC members engage and discuss to the point of consensus on individual papers and in the program as a whole. In practice however, things are not as simple and at the other extreme, conference programs are viewed as expressions of the PC chair's preferences, aided by the help of the PC committee feedback. As a result, often PC chairs end up taking a more pro-active role in the process, especially in borderline cases for which e.g., 2-3 positive reviews are facing a reject position. PC chairs will then often need to make a decision, despite some opposition either way from several committee members in the written reviews and discussion phase or in the PC meeting. The makings of a dictator. In a true democracy, this ability of the PC chair to proactively solve borderline cases should be used sparsely, only for good. In practice however, its existence opens the door for significant overuse. Here is the ideal scenario for a dictatorship: a conference with a fixed number of presentation slots, most of which cannot be filled with clear signals from the PC, e.g., due to a majority of papers receiving mixed reviews, e.g., at most 2 accepts out of 3 reviews. Now, the PC chair has to step in and save the day for borderline papers under the pressing requirement that "we need more papers", in the process becoming a most noble hero or a (hopefully at least enlightened) dictator. This effect is further compounded by the fact that very often only the PC chair has a global view of the state of the conference, its acceptance slots and reviewers behavior. How often does this happen? Very often. In many of the selective conferences I recently have been involved in only a statistically insignificant handful out of the hundreds of submissions end up with more than 2 positive reviews. Yet, should the PC chair be faulted for reviewers inability to decide? Probably not. To understand whether something can be done, we discuss now a case study. 5. The ISOC Network and Distributed Systems Security Symposium (NDSS) NDSS has been established in 1993 and has evolved to be one of the top research conferences in the broader cyber-security arena. We wont discuss here research-specifics of NDSS. In the past 5 years, NDSS acceptance rates have ranged from 11.8% to 18.3%. The tentative target acceptance rate we have set for this year's conference is 18%. At the time of writing we are -- in the words of former Vice President Dick Cheney -- "in the last throws" of the NDSS written peer review process, pre - PC meeting. In this stage, papers receive 3-5 reviews from assigned PC members, quantifying the level of acceptance from strong reject all the way to strong accept and in-between. As discussed above, in an ideal world, the deliverable of this process is a ranked list of papers out of which the top e.g., 18% can be directly accepted for publication and presentation. In NDSS however (as in a majority of other recent top tier systems and security conferences), the way the initial output was shaping suggested a very difficult time in ranking. In the initial phases of the process, less than 7% of papers were ending up with more than 2 accept ratings in each batch of 3-5 reviews. This presented the relative bleak outlook of having a set of vocal 5-minute arguments at the PC meeting aid the PC chair (me) to decide in 10-15 minutes on the merit of the remaining borderline 11% of the submissions. 6. The R3 Rule Did I feel a twinge of dictatorship joy you may ask? Absolutely. Yet my extreme selfishness prevailed and it simply seemed more fun to instead explain what is going on. It is relatively obvious that the solution to this problem involves having the PC members be a bit more positive in their reviews. However, when suggesting this to PC members I was faced repeatedly with the following response: "In my pile of 16, I have favorably rated 3 papers, which is exactly 18% of the pile, the target conference rate". It then became immediately clear that: (i) no one reads PC chair emails, and (ii) there is a need to bring to the community's attention an important simple fact on setting PC reviewing selectivity expectations. We now turn to simple 10th grade probabilities. Denote by a the target conference acceptance rate (in our case a=18%), x the individual reviewers selectivity, and pi the probability that a paper with i positive reviews is ultimately making it into the final program. We further simplify
our lives by considering a total of 3 reviews/paper (increasing the number of
reviews only strengthens the case), making
which, has the following meaningful solution [10] for x
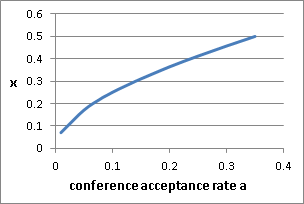
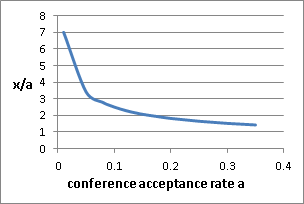
For
Thus, in order to make herself heard in the final program, out of a pile of 16, a reviewer should suggest which 5-6 papers are at the top (which was what the original PC chair message that probably no-one read was suggesting). We will call this the prevent Radu from being a dictator Reviewing Rule (R3). Interestingly, the R3 rule is more relevant for increasingly selective conferences, with factors ranging from 1.5 for a 30% acceptance rate conference, all the way to 3.4 for a 5% venue. Yet, what about the non-correlated reviews assumption? In the case of correlated reviews (an intuitive assumption if one believes in some absolute inherent universally recognizable quality of a research paper), we should probably not assume independent variables. Yet, if correlation were to be considered it would only strengthen the rule, since it would in effect clump together reviews of the same (positive or negative) nature and thus further reduce the number of papers with 2 or 3 reviews in the entire batch from which to chose from. Moreover, in practice, a large number of papers received reviews ranging relatively uniformly from strong reject to strong accept which is exactly the reason we find ourselves investigating this to begin with. Semantics. But, while the behavior of the R3 rule is relatively clear, what does it truly mean? The R3 rule simply expresses the impact of the target conference acceptance rate on the individual PC members acceptance rates. It should not be used to force reviewers to rate higher than they prefer. They should have the option to reject all the papers in their pile. In that case, however, the rule clarifies the fact that if the overall acceptance rate is preset, their selective behavior will simply ensure they lose their voice in the process and force the PC chair and the PC meeting to make the decision for them. The R3 rule is about having one's voice heard in the final program and ultimately about enforcing democracy in the conference reviewing process. 7. Better solution? Do we have a better reviewing system? Well we should first define better. Much ink has been spent on writing on this topic [5,8-9] and will continue to be. Ultimately, the status quo is difficult to abolish especially since such insights are not available to the community at large and deploying something like the R3 rule takes away the main perks of the PC chair job: power and fame. It would be interesting to see whether having reviewers not accept/reject but instead rank the papers in their pile would result in less fuzziness in the process. An automated reviewing algorithm, gently shepherded by the PC chair can then use these ranked lists to spit out the best 18% of papers. A ranking system defeats extremely "selective" hypercritical [7] reviewers who reject most of the things they see. Naturally, this would hardly be popular as it takes away even more perks from individual reviewers this time. There is nothing in the world that compares with the wonderful feeling of uttering opinions and being given the opportunity to assign a reject rating on others' work. Of course, to complicate things further, such a mechanism has its own problems mostly centered around the definition of "best" which still needs to be defined and for centuries has not yet been, when occurring in very similar election mechanisms [6]. 8. Take home some cake and eat it too. So what have we learned? Conference acceptance rates are less meaningful than we may think. Individual paper quality should probably not be judged solely by the acceptance rate of the conference in which it appeared. When participating in or chairing a program committee, to defeat dictator PC chairs and ensure one's voice is heard in the process, reviewer expectations should be set according to the R3 rule and not to the common misconception of matching the target conference acceptance rate. Happy Reviewing!
References [1] List of Computer Science Conferences [2] DBLP: Computer Science Conferences and Workshops [4] Kevin Almeroth, Systems and Networking Conferences Statistics [5] Dan S. Wallach, Viewpoint: Rebooting the CS Publication Process. Communications of the ACM, October 2011 [6] A survey of voting Systems, http://en.wikipedia.org/wiki/Voting_system [7] Vardi, M.Y, Hypercriticality, CACM, 53, 7, 5, July 2010 [8] Chen, J. and Konstan, J.A., Conference paper selectivity and impact, CACM, 53, 6, 79-83, June 2010 [9] Wing, J.M., Lemire, D. and Chi, E.H., Reviewing peer review CACM, 54, 7, 10-11, July 2011 [10] Wolfram Alpha
Comments (received directly)
(further comments can be made/read on the blog)
"Radu, I read your article with high interest. The equation and curves you found are great. Indeed the notion of rating papers in a pile at the conference acceptance rate is a grand myth. I like the ranking idea, one could use it as a secondary metric so reviewers still have the power of a crushing review grade. Clearly the whole problem is similar to that in elections where models have also been proposed to rate candidates (which we do now for conferences) and not vote (which we do now) or also rank. I'll forward your note to my current co-chairs for X." (January 16, 2012) "Being Academically serious is as good as being seriously academic, both can be translated to being irrelevant!" (January 15, 2012) Summarized (by me) comment: This is not how the PCs work in my community. Instead the program is the result of mostly online discussion and a consensus is reached on which papers to accept. (November 11, 2011) Summarized (by me) comment: This paper is rather pretentious and aims to formalize a simple thing. The entire problem can be easily solved by score normalization and acceptance of the highest scored papers. Also, PC members do not serve for "power" but rather for "civic duty". Democracy is not good for scientific reviewing. One should justify the claim if one believes otherwise. (November 11, 2011) Summarized (by me) comment: This article makes an important point. The conclusions can help the community currently struggling with very low acceptance rates. It is important to also consider the case of reviewer score correlation: for example in the case of perfect correlation among all referees, then obviously each referee should rate exactly at the conference acceptance level. (November 11, 2011) Summarized (by me) comment: The paper raises an important issue. The author should explore more general cases and the dictator slant should be toned down. In most of the conferences I have been involved in PC members make the decision, not the chairs. I certainly could never identify with the "chair as a dictator" when chairing. The author is correct however about the basic phenomenon of papers not receiving enough positive reviews. One important advice to reviewers would be to focus comments more on what is positive in the paper, especially if they chose to "accept" it. Also the reader may want to look at Thomas Anderson's essay Conference Reviewing Considered Harmful which discussed that SOSP 2009 was planning to use ranking in reviewing papers. (November 11, 2011) Summarized (by me) comment: The author points out a real problem: conference reviewing can be done either well or not so well. However I have almost never run into the scenario discussed. Most reviewers are smart. I agree however that hypercriticality is a problem. I am not sure that acceptance rates of 10% and below are statistically irrelevant -- any proof for that? Also, 3 reviews/paper doesn't seem enough to me, 5-6 is more like it. Often what really happens in practice is that a PC member may claim to be the top expert of the batch and reject the paper. PC members should be chosen for their willingness to do the work assigned by the PC chair instead of arguing about acceptance rates. Vigorous online discussions pre-PC meeting is important! Review scores should NOT be made too relevant in the final acceptance decision -- once the decision has been made to discuss the paper in the PC meeting, the scores should become irrelevant. The argument that "paper X scored better than paper Y therefore we should prefer paper X to paper Y" is foolish. The reason I chose the PC chair role is not for power but because I want to serve the community. I don't think ranking is unpopular because it takes away perks from reviewers but because it requires lots more work. (November 11, 2011)
|